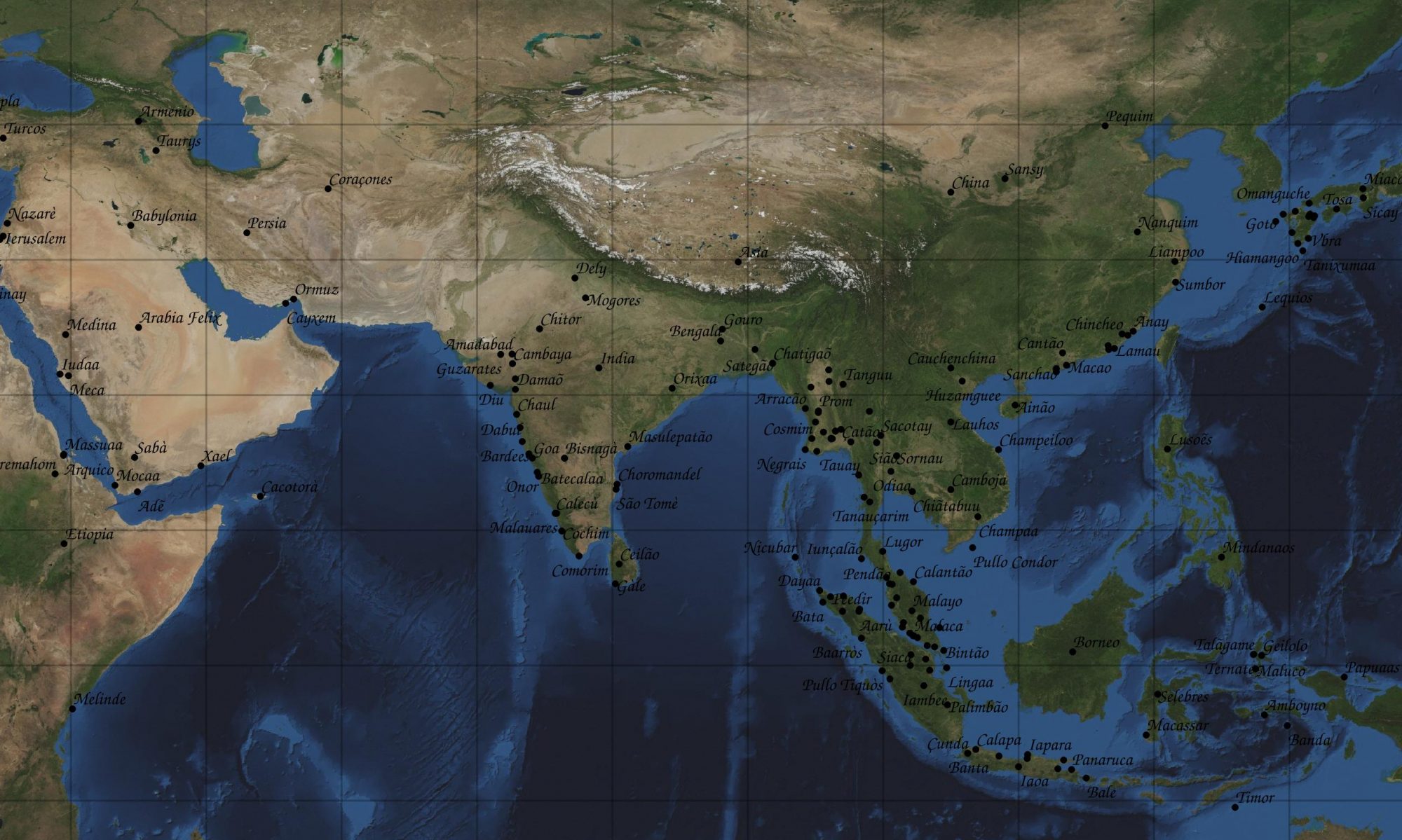
Levantamento de entidades geográficas
- Fichas. Faz-se um inventário por fichas de entidades a partir de repetidas leituras do texto em:
- Facsímile do original da Biblioteca Digital da Biblioteca Nacional de Portugal.
- Lopes da Costa (ed. e rev.). Fernão Mendes Pinto and the Peregrinação. Restored Portuguese Text. Jorge Santos Alves (ed.). Fernão Mendes Pinto and the Peregrinação. Lisbon. Fundação Oriente. 2010. Vol. II.
- Peregrinaçam. Documento digital. Edições Vercial.
- Listado estruturado. A partir das fichas cria-se um listado, em formato .csv, que recolhe:
- Uma entrada principal para cada entidade geográfica (parelho ao lexema para nomes comuns). Ex. Cauchenchina
- As variantes com que aparece a entidade geográfica no texto. Ex. Cauchenchina, Cauchim, Cauchins.
- A categoria da entrada principal (nome próprio por defeito, gentílico se só aparece no texto como adjectivo).
- Indice primário. O listado volca-se numa base de dados e cria-se um índice para cada entrada que servirá de referência para a sua recuperação.
- Indice de variantes. A partir da tabela de lexemas, cria-se uma nova tabela que indexa todas as variantes de cada entidade geográfica, quer gráficas, quer gentílicos.
Elaboração de um corpus para o estudo das entidades geográficas
- Anotação. Anota-se cada uma das entidades geográficas registadas no conjunto do texto a partir do listado de variantes.
- Segmentação por capítulos. Com o texto já anotado, cria-se um ficheiro texto de cada capítulo para optimizar pesquisas e facilitar o indexado das entidades geográficas.
- Control da anotação de entidades geográficas. Para cada variante indexada, comprova-se que aparece no texto e realizam-se correções se proceder.
- Correção. Detetam-se variantes que não aparecem por leituras equivocadas, gralhas ou resultado de realizar o levantamento desde distintas edições (ex. diferenças na anotação da nasalidade).
- Alguns termos aparecem anotados várias vezes por aparecerem como parte de uma forma complexa (e.g. Çambilão e Pullo Çambilão).
- Aproveita-se o control para recolher dados sobre a frequência de variantes em cada capítulo.
- Segmentação por orações. A partir da tabela de capítulos (para facilitar o indexado), segmenta-se o conjunto do texto por orações.
Escolhem-se o ponto (.), a interrogação (?) e exclamação (?) como delimitadores oracionais. Criam-se excepções para abreviaturas e datas e quantidades em números que levam sistematicamente um ponto no texto, para serem obviadas na segmentação. Eliminam-se também os cabeçalhos com o título de capítulo em Romanos do original, elemento de marcagem mais que conteúdo. - Control da anotação por orações. Buscam-se ocorrências para cada varianten no listado de orações.
Atualizações
Ao trabalhar sobre o corpus precisa-se atualizar as bases de dados segundo se acham entidades não anotadas, se reorganiza a sua classificação ou se reestruturam as tabelas para trabalhar com ferramentas PLN e SIG.
- Ordem da lista de variantes de um lexema
As variantes adicionam-se segundo vão aparecendo no corpus e no caso de serem adicionadas como resultado de trabalho sobre o corpus (casos não considerados inicialmente, omissões na anotação inicial), entram nas últimas posições da tabela de variantes. Os scripts de saída e consulta podem ordenar automaticamente a saída dos dados segundo preferências do usuário, por defeito, estabelece-se uma ordem alfabética para a lista de variantes baixo cada lexema. - Seleção da variante com a frequência mais alta como lexema
O representante das variantes de uma mesma entidade geográfica é escolhido a partir da frequência mais alta. Se mais de uma variante tem a mesma frequência com o valor mais alto, ordenam-se alfabeticamente e escolhe-se a primeira.
Resultados
O resultado mais direto é o índice de entidades que permite recuperar as concordâncias no corpus a partir das anotações de topónimos e gentílicos.
Os capítulos 117-131, referidos aos episódios com os Tártaros, foram alinhados com os correspondentes da primeira tradução inglesa para criar um corpus paralelo chamado de corpus da Tartária.
Publicações relacionadas
Algumas publicações que descrevem o processo de elaboração do corpus e metodologias específicas no trabalho com as entidades geográficas mencionadas.
Canosa, A. X. (2019). Referentes por coordenadas e georreferências relativas das entidades geográficas mencionadas na Peregrinação. In C. Pazos Alonso, V. Russo, R. Vechi & C. Ascenso (Eds.), De Oriente a Ocidente: Estudos da Associação Internacional de Lusitanistas (vol. I, pp.11-34). Coimbra: Angelus Novus. https://lusitanistasail.press/index.php/ailpress/catalog/book/164
Canosa, A. X. (2018). Comparison of Segmentable Units as Indicators of Two Texts Being Parallel. In 7th Symposium on Languages, Applications and Technologies. http://drops.dagstuhl.de/opus/volltexte/oasics-complete/oasics-vol62-slate2018-complete.pdf#page=189
Canosa, A. X. (2017). Validação de termos de domínio por meio de uma base lexical-semântica difusa. Tradterm, 30. http://www.revistas.usp.br/tradterm/article/view/141821
Canosa, A. X. (2017). Algumas interseções disciplinares na recuperação da geografia da Peregrinação de Fernão Mendes Pinto. Fluxos e Riscos, 2(2), 23-43. http://www.academia.edu/35547657/Fluxos_and_Riscos_Vol.2_No_1_2017_